시간 복잡도 (음.. 영어로는.. time complexity?)
어떤 문제에 대한 알고리즘이 여러개 있다고 할 때, 그 알고리즘들 중에 어느 것이 나은지를 평가하는 것은 매우 까다롭습니다. 단순하게 소스 길이로만 측정할 것도 아니고, 입력 데이터에 따라 프로그램의 속도도 제각각이기 때문입니다. 작성하기 쉽다, 어렵다는 사람에 따라 다르니 객관적인 방법이 될 수 없겠지요.
더구나 하나의 알고리즘이라 해도 실행되는 컴퓨터, 운영체제, 언어, 프로그래머에 따라 프로그램이 보여주는 성능은 천지차이입니다. 따라서 이러한 요소들이 배제된, 객관적인 알고리즘 평가/측정 방법이 필요는데, 그 때문에 태어난 것이 바로 시간복잡도입니다.
예를 들어, 퀵소트와 버블소트를 예로 들면, 소스의 길이나 복잡함의 정도는 퀵소트가 훨씬 더 합니다. 하지만 성능상으로 보면 일반적인 경우 퀵소트가 버블소트보다 훨씬 더 나은 성능을 보여 줍니다. 이것은 퀵소트가 버블소트보다 더 낮은 시간복잡도를 가지고 있기 때문입니다.
시간복잡도를 표기하는 방법에는 여러 가지가 있는데, 일반적으로 사용되는 것이 O표기법입니다. 이 O표기법은 최악의 경우에 대한 성능을 나타냅니다. 알고리즘의 성능을 측정할 때 중요한 것이 바로 '최악의 경우(worst case)'입니다.
예를 들어서 서버와 클라이언트 사이에 통신이 이루어 진다고 할 때, 평균 10ms의 응답시간을 보여준다고 해서 좋은 네트워크 시스템이라고 보기는 어렵습니다. 어떤 데이터의 경우는 100ms의 지연시간이 생긴다면 문제가 있는 시스템인거죠. 하지만 최악의 경우에도 20ms의 응답시간을 보여준다고 할 때에는, 훨씬 더 신뢰성 있는 시스템이라 생각할 수 있습니다.
알고리즘의 경우에도 마찬가지로, 어떤 특정한 데이터에 대해서만 빠르다면 그 알고리즘이 좋다라고는 말할 수 없을 것입니다. 최악의 경우가 알고리즘 분석의 척도가 되는 것은 바로 이런 이유에서입니다.
알고리즘 성능 측정을 하기 위해서는 기본 단위가 있어야 합니다. 예를 들면 기계어 코드 하나가 1단위다.. 라고 생각할 수 있겠죠. 하지만 컴파일러나 CPU에 따라 코드의 길이는 달라질 수 있기 때문에 좋은 방법이라고 하기는 어렵습니다. 객관적인 단위로 생각할 수 있는 것들은 비교, 대입, 사칙연산 등등이 되겠죠. 하지만 이런 것들은 측정하기엔 너무나 작기 때문에 너무 불편합니다.
따라서 보통 시간복잡도를 정할 때에는 먼저 기본 단위를 정해주어야 합니다. 이것은 문제 마다 달라질 수 있습니다. 그럼 알고리즘의 객관적인 비교가 어렵지 않을까.. 라고 생각할 수도 있습니다. 이런 문제를 해결하기 위해서는 기본 단위의 시간복잡도를 O(1)인 것으로 정해주어야 한다는 것이죠
O(1)은 모든 연산을 한번한 한다는 뜻은 아닙니다. 단지, 입력데이터의 크기나 종류와 무관하게 항상 같은 성능을 보여준다는 뜻입니다.
예를 들어서 두 변수를 교환하는 다음의 알고리즘은 시간복잡도가 O(1)입니다.
swap (a, b)
t <- a;
a <- b;
b <- t;
위의 알고리즘은 a, b가 어떤 값을 갖고 있는지와는 무관하게(즉, 상수시간에) 일을 끝마칩니다. 이런 알고리즘은 O(1)의 시간복잡도를 갖습니다.
시간복잡도가 O(1)인 기본 동작으로 정했다면 이제 알고리즘에서 이 기본 동작이 얼마나 실행되는가를 보면 그 알고리즘의 시간복잡도를 알 수 있습니다.
다음과 같은 정렬 알고리즘이 있다고 합시다
sort (A, n)
for i <- 1 to n-1
for j <- i+1 to n
if A[i] > A[j] then swap (A[i], A[j]);
위의 경우에는 swap을 기본 동작으로 보기는 어렵습니다. 예를 들어 A란 배열이 이미 정렬이 되어 있는 상태라면 한번도 swap함수는 실행되지 않는데, 그렇다고 해서 이 알고리즘이 순식간에 끝난다고 말할 수는 없기 때문이죠.
여기서는 >, 즉 비교 연산자를 기본 동작으로 정하겠습니다. 그럼 이 알고리즘에서 > 가 몇 번이나 실행되는가를 알아야 합니다. 이것은 약간의 계산이 필요한데...
i가 1일 때 : n-1회 실행
i가 2일 때 : n-2회 실행
...
i가 n-1일 때 : 1회 실행
약간의 수학적인 방법으로 계산하면, {(n-1)*(n-1+1)}/2 = (n^2 - n)/2가 됩니다.
따라서 이 알고리즘의 시간복잡도는 (n^2 - n)/2라고 말할 수 있죠.
O표기법은 이 시간복잡도에서 계수가 없앤 최고차항만을 써주면 됩니다. 최고차항이 아닌 것들은 별 필요가 없기 때문인데요... 아무튼 O표기법으로 나타내면 O(N^2)이 됩니다.
이 알고리즘이 N이 100일 때 1초의 시간이 걸렸다면, 200일 때는 시간이 얼마나 걸릴까요? 약 4초의 시간이 걸릴거라 예상할 수 있습니다. 시간복잡도가 O(N^2)이라는 것은 실행시간이 입력데이터에 대해 제곱에 비례한다는 것을 말해줍니다. N이 300이라면 약 9초의 시간이 걸리겠죠.
시간복잡도에서 최고차항에서 계수를 빼는 것은 이러한 이유에서입니다. 계수는 입력데이터에 따라 크기가 변하지 않기 때문에, 컴퓨터의 성능, 컴파일러의 종류등의 요소가 가미되면 별 의미가 없어집니다.
예를 들어 10N, 과 0.2N^2의 시간복잡도를 갖는 두 알고리즘이 있다고 합시다. N이 작다면 분명히 0.2N^2의 알고리즘이 훨씬 더 빠를 것입니다. N이 20이라면 10N알고리즘은 200, 0.2N^2알고리즘은 80의 계산시간을 필요로 합니다. 이때는 0.2N^2알고리즘의 효율적이라고 할 수 있죠. 하지만 항상 그럴까요?
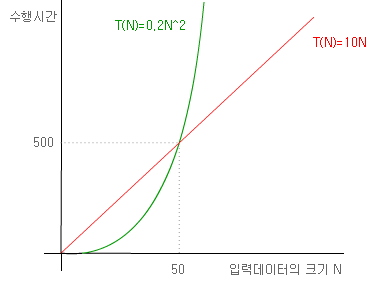
N이 100일 때를 생각해 봅시다. 10N알고리즘은 1000, 0.2N^2알고리즘은 2000의 계산시간이 필요하게 되죠. 10N알고리즘이 훨씬 효율적이라는 것을 알 수 있습니다. 계산해 보면, 0.2N^2의 알고리즘이 더 좋은 성능을 보여주는 것은 단지 N이 50보다 작을 때입니다. N이 커지면 커질수록 0.2N^2의 알고리즘은 비효율적입니다. N이 10000일 때의 경우를 생각해 보시면 아시겠죠. (십만과 이천만의 차이..)
O표기법에서 계수 없는 최고차항만이 쓰이는 것은 바로 이러한 맥락에서입니다. 최고차항의 차수가 알고리즘의 성능을 나타내죠.
그런데 모든 알고리즘에 대해서 이렇게 기본 동작의 단위를 일일이 계산할 수는 없는 일입니다. 따라서 단순화시켜서 생각해야 하는데, 루프가 최고 몇 중으로 겹쳐져 있는지를 보면 대충 알 수 있습니다. 다음과 같은 경우는,
for i:=1 to n-3 do
for j:=1 to 3 do
for k:=1 to n*n do
for l:=1 to n/2 do
for m:=1 to 8 do
...;
위의 소스에서 ...부분의 시간복잡도가 O(1)이라면, 위의 알고리즘은 시간복잡도가 O(N^4)이 됩니다. (여기서는 i, k, l이 시간복잡도에 영향을 줍니다)
물론 이런 방법만으로 모든 알고리즘의 시간복잡도를 결정할 수는 없지만 대충의 측정은 가능 하지요. 보통 logN은 분할정복(divide and conquer) 알고리즘을 사용할 때 붙고, 2^N이나 N!의 경우는 재귀호출같은 '무식한' (어떤 책에서는 '저돌적인'이라는 표현을 썼더군요) 알고리즘에서 보입니다.
가장 좋은 성능의 알고리즘은 바로 O(1)입니다. 입력데이터의 크기에 관계없이 항상 일정한 시간만을 필요로 합니다. 대체로 다음과 같은 순서로 복잡도가 크다고 할 수 있습니다. 시간복잡도가 높을수록 데이터의 증가에 따라 수행시간이 기하급수적(!)으로 늘어납니다.
O(1), O(logN), O(N(1/2)), O(N), O(NlogN), O(N^2), O(N^3), O(2^N), O(3^N), O(N!)
O(NlogN)은 N에 logN을 곱한겁니다. 이때 log의 밑은 항상 2입니다. (밑이 2인 log를 lg로도 나타내죠..) 퀵소트의 시간복잡도가 O(NlogN)인데, 힙소트, 머지소트 등도 마찬가지로 O(NlogN)의 시간복잡도를 갖습니다. 일반적으로 데이터 정렬의 시간복잡도의 하한은 O(NlogN)인 것으로 증명되어 있습니다. 따라서 퀵소트보다 시간복잡도가 낮은 알고리즘을 개발하려고 애쓰는 것은 "삽질"이 되겠습니다. -_-;
O(2^N)은 보통 N개의 원소를 갖는 집합에서 모든 부분집합을 만들어서 답을 구하려 하는 알고리즘을 만들 때 나타나는 시간복잡도입니다. N이 조금만 커져도 (예를 들어서 N이 24만 되어도 천육백만번을 계산해야 합니다) 거의 사용이 불가능한 알고리즘이라 할 수 있죠.
O(N!)은 N개의 원소를 순서대로 나열하는 순열을 만들어서 답을 구하려는 알고리즘을 만들 때 나타나는 시간복잡도입니다. (n-queen이나.. TSP의 경우죠) O(2^N)보다도 더 최악의 성능을 보여줍니다.
예로 N이 24일 때, 620448401733239439360000번을 계산해야 한다는 것이죠.
시간복잡도 이외에 공간복잡도라는 것도 있습니다. 입력데이터의 크기에 따라 어느 정도의 저장공간이 필요한지를 알고 싶을 때 사용합니다. 하지만 공간복잡도는 시간복잡도보다 클 수 없고(이유는 생각해 보시길..) 메모리는 CPU보다 훨씬 싸기 때문에 :) 비중있게 생각하지는 않습니다.
보통 대회에서는 16bit 컴파일러는 쓰게 되는데 그것 때문에 64kb의 메모리만을 사용하게 되는 제약이 생깁니다. 따라서 문제를 풀 때에는 메모리 사용량을 최소화해야 하는 것이 필요하구요.
10초를 기준으로 할 때 컴퓨터의 수행시간의 한계는 보통 천만~1억번 정도로 생각하시면 됩니다. N의 크기가 100인 문제가 있다면 보통 O(N^3)의 성능을 갖은 알고리즘을 필사적으로 생각해야 할 것입니다. (혹은 계수가 작은 O(N^4)알고리즘도 괜찮겠지요)
항상 시간복잡도가 낮은 알고리즘이 좋다고는 말할 수 없겠지요. 작성하기 쉽고, 소스 길이가 짧고, 쉽게 생각할 수 있는 알고리즘이 좋은 경우도 얼마든지 있습니다. 적당한 선에서 절충해서 생각해야 할 문제입니다.